Writes Dr. Daniele Metilli, Research Fellow in Advanced Data Architectures.
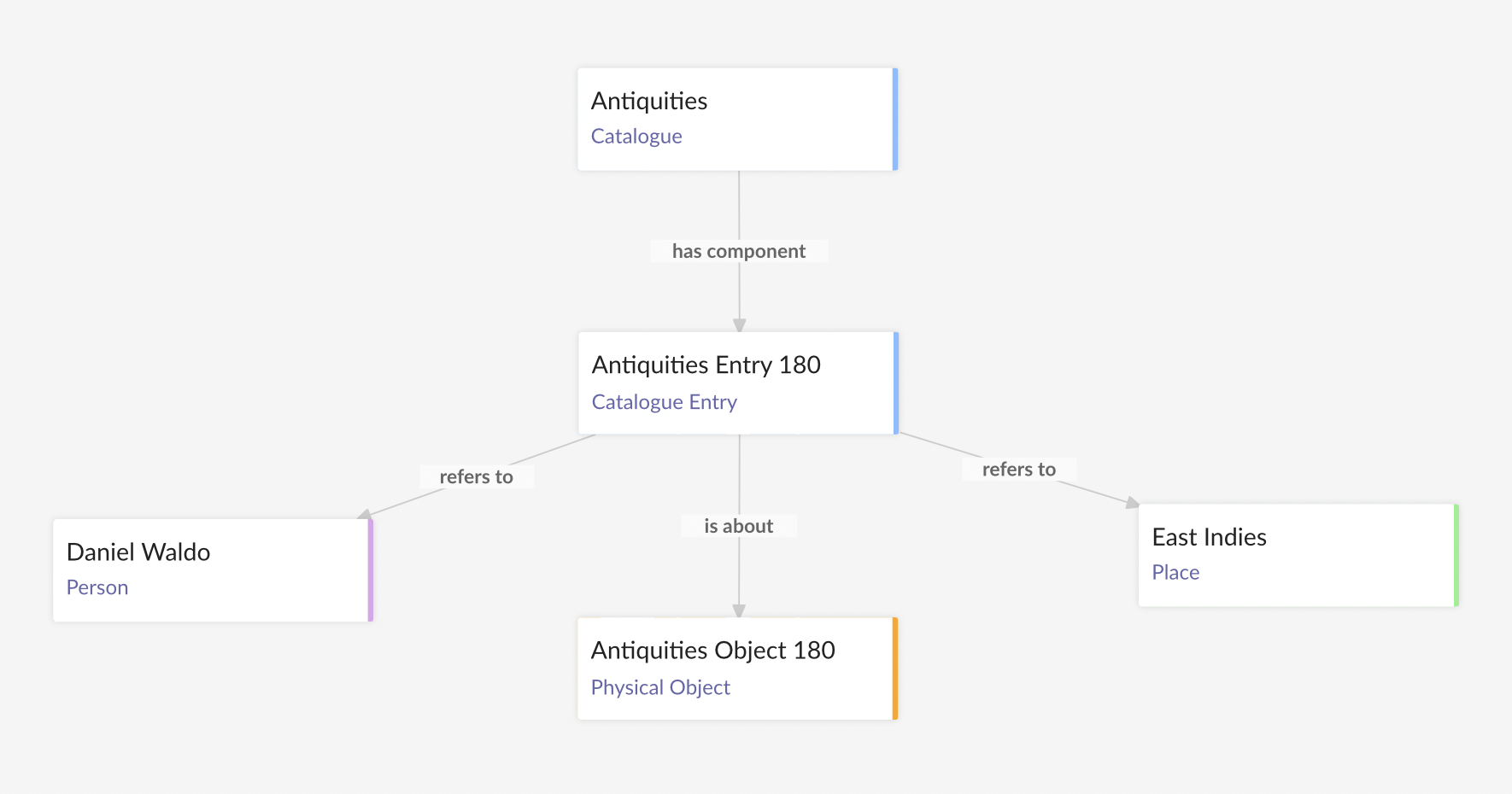
The Sloane Lab technical team has recently developed a prototype of the Sloane Lab knowledge base. The knowledge base aims to unify the dispersed data of the Sloane collection and it can be seen as the combination of a data model, which describes the main concepts in a certain domain of reality and the relations among them. The aggregated data originate from disparate datasets that describe individual entities such as catalogue records, objects, people, etc.
Our data model is based on an existing standard called CIDOC CRM, published by the International Council of Museums. We use a subset of this standard model and extend it where needed to address the specific requirements of the project that relate to the aggregation of historical records. Our main focus is on the historical and contemporary catalogues, which we view as different types of “information objects”. Each catalogue record is generally about a single physical object but may contain references to other entities of interest such as people, places, or time.
Currently, the datasets that are stored in the knowledge base include the Miscellanea and Fossils I and V historical catalogues. We are also starting to import samples from the Natural History Museum and British Museum catalogues. These datasets follow different description practices and are stored in different formats. By mapping each of them to our data model, we will make it possible to analyse, query, and visualise the entirety of the aggregated data through an interactive interface.